
If you are going to capture data from invoices, bills, questionnaires, application forms, or any other documents, there is no need to recognize the whole document and search for the data in it. Instead you can recognize only certain text fields of a document and directly capture data from these fields into an information system or database.
Another situation when text field recognition is useful is when images you want to process contain only a few words of text. This text can have specific format, e.g. e-mail, date and time.
In the first case you will need to process the region of an image, which contains a short text fragment from certain field of a document, in the other case — a small image with only a few words of text. In both cases, you should use text field recognition.
ABBYY Cloud OCR SDK is only available after registration. If you are not a registered user yet, please follow the link to register. During registration you will receive login and password for Cloud OCR SDK site and create Application ID and Application Password necessary to access the processing server.
After registration you can use Cloud OCR SDK for text field recognition.
To recognize text fields, use the processTextField method with recognition parameters suitable for your image:
- Specify the region of a text field via the region parameter of the method. The region should contain only the field you want to recognize.


You can also pass the image of a single field to the method. In this case there is no need to specify the region of the field—by default the whole image is recognized. If you crop the image of a field from a bigger image, do not decrease image resolution while cropping.
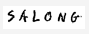

- Specify recognition language of the text in the field. This is done via the language parameter of the method. Note that not all languages are available for handprint recognition. See the list of recognition languages for details.
If the field can contain only a set of characters, e.g. only Latin characters with no punctuation marks, or only digits, you can use the letterSet parameter to specify the set of characters, which should be used during recognition. -
Specify the correct type of text in the field. For example, if the field contains handprinted text, specify the handprinted text type in the textType parameter. See several examples of text types below and all available text types.

handprinted text type 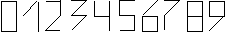
index text type—digits written in ZIP-code style 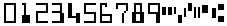
e13b text type—digits and A, B, C, D characters printed in magnetic ink You can specify several text types for one field. In this case the most suitable text type is selected during recognition and the entire text within the region is recognized with this selected text type. If you need to recognize text fragments of different types, draw separate regions for each type of text.
-
For handprinted text only. Letters in a field which contains handprinted text can often be enclosed in a frame, box, etc. In this case you should use the markingType parameter. For the correct operation of this parameter, please use the placeholdersCount parameter which sets up the number of character cells in the region.
If text in the field looks like: Select the markingType value: Specify the correct value of the placeholdersCountparameter Plain text simpleText No Underlined text 
underlinedText No Text enclosed in a frame 
textInFrame No Text in white fields on a gray background 
greyBoxes Yes The field is a set of separate boxes 
charBoxSeries Yes The field where the text is located is a comb 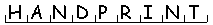
simpleComb Yes The field where the text is located is a comb and that this comb is also the bottom line of a frame 
combInFrame Yes Text in a frame and this frame is split by vertical lines 
partitionedFrame Yes -
For handprinted text only. You can additionally specify the writingStyle parameter which provides additional information about the writing style of the handprinted letters. Examples of various numeral writing styles:
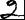
Russian two 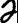
American two 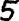
"ordinary" five, can occur in any style 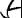
Japanese five 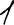
Russian one 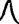
German one 
"ordinary" nine, can occur in any style 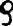
Czech nine with the ring on the right 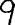
American nine without the "hook" at the bottom -
If the field contains data in a specific format, e.g. date, time, e-mail address, invoice number, you can specify a regular expression which defines the words allowed in the field. This is done via the regExpparameter. For example, the regular expression for e-mail address looks like this:
[a-zA-Z0-9_\-\.]+\@[a-zA-Z0-9\.\-]+\.[a-zA-Z]+
Note that regular expressions do not strictly limit the set of characters of the output result, i.e. the recognized value may contain characters which are not included into the regular expression. During recognition all hypotheses of a word recognition are checked against the specified regular expression. If a given recognition variant conforms to the expression, it has higher probability of being selected as final recognition output. But if there is no variant that matches regular expression, the result will not conform to the expression. See the description of regular expressions for details.
- You can also constrain the number of lines in the field, or the number of words in a line using the oneTextLine and oneWordPerTextLine parameters.
Call the processTextField method with the specified parameters. A new processing task will be created on the server.
Monitor the task status in a loop using the getTaskStatus method until the task is processed. The result of processing is returned in XML format and can be downloaded by the reference provided in the XML response. The output XML file has the following format:
<?xml version="1.0" encoding="utf-8" standalone="yes"?> <document xmlns="@link" xmlns:xsi="@link" xsi:schemaLocation="@link" version="1.0"> <field left="0" top="0" right="559" bottom="104" type="text"> <value encoding="utf-16">JENNIFER</value> <line left="49" top="26" right="520" bottom="96"> <char left="49" top="31" right="105" bottom="96" confidence="83">J</char> <char left="121" top="26" right="161" bottom="81" confidence="100">E</char> <char left="179" top="28" right="216" bottom="81" confidence="64">N</char> ... </line> </field> </document>
It contains the recognized value of the field and coordinates and confidence of recognition for each character.
You can view implementation of this procedure in code samples for some of the programming languages and platforms.
Consider also using of the processFields method, which allows you to process several fields in one request.