Hi,
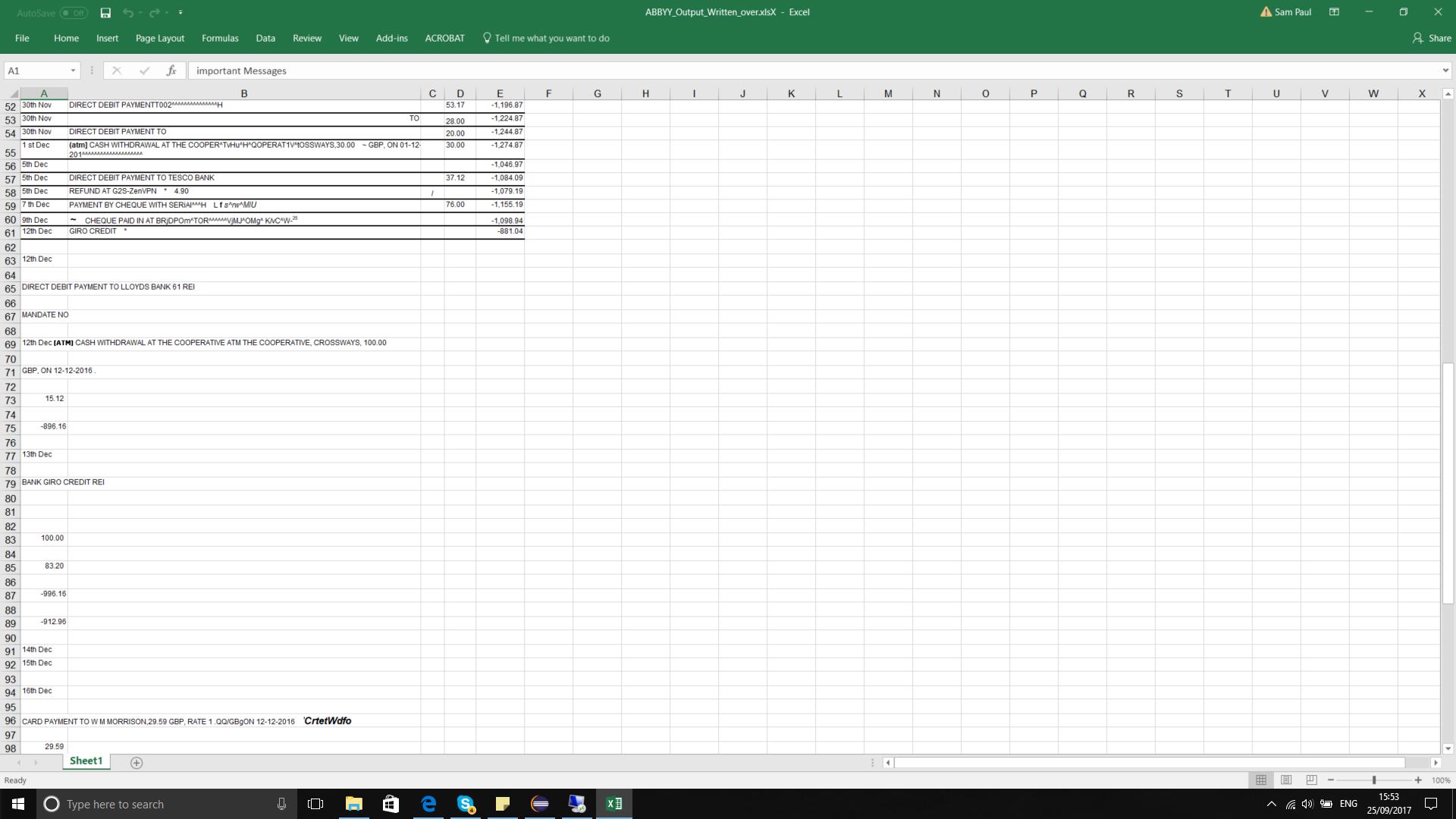
I have been using ABBYY's OCR SDK (pdf to excel conversion)for a while testing it with different documents and most of the documents come out perfectly except this document(attached : Written_over_Redacted.pdf). The output (attached : error.png) comes out distorted. Is there anything I can do to improve the quality ?
{kind=link}
Comments
4 comments
Hi,
The issue is hidden in fact that the table in your file has no vertical separators. Therefore table is not detected and the output gets split line by line. ABBYY Cloud OCR SDK does not provide you ways to change these settings. I can suggest one of the following workarounds:
• Export to .txt. Txt by default retains the layout of file, therefore the output is formatted like original.
• Export to .xml and parse .xml text coordinates manually. ABBYY does not provide .xml parser for data extraction, but you can implement it yourself.
If you are willing to extract data from such tables please consider using FineReader Engine, which will give you access to a wider specter settings. In particular, it will allow you to extract the data from similar files in the form of tables.
Hi,
Thanks. I'll try this. Is the FineReader Engine different from the Cloud OCR SDK? When I try to access the Engine I get redirected to the Cloud OCR SDK. Can you please give me the link to it.
The FineReader Engine is a separate SDK, that is not located in cloud. The FineReader Engine allows you to run recognition process on your local machine (or several machines) without sending images to our server.
Here you can find its description on ABBYY official website: www.abbyy.com/ocr-sdk/.
I will recommend you can also try PDF to Excel Converter to bulk export PDF to XLSX format. It easily saves multiple PDF files into Excel format to save PDF data into XLSX format without any data loss.
Read More Information About This Software:- http://www.stillbonsoftware.com/pdf-to-excel/
Please sign in to leave a comment.