Hello,
In the document definition Editor, when I run an extraction Test, I have this result for a field :

This is how the field looks on the document
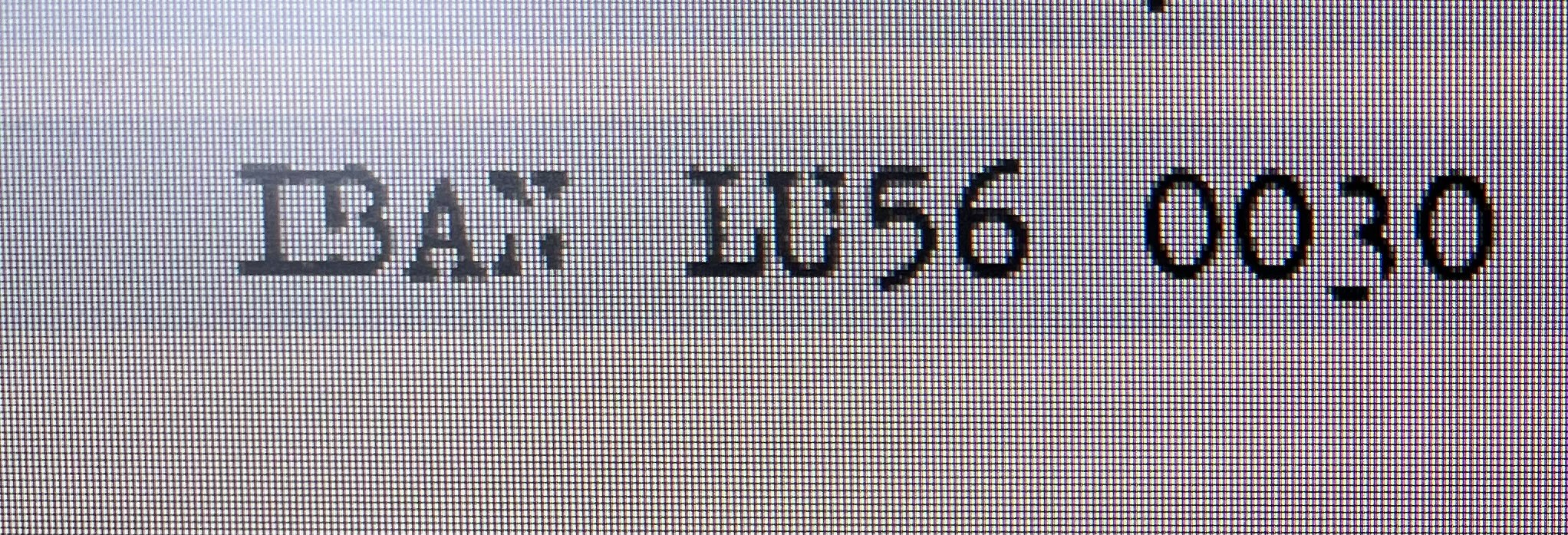
When I simply reduce the extraction zone from some pixels to the right (just to reset the field or idk what is happening in Abbyy exactly),

Then the text extracted is perfectly well recognized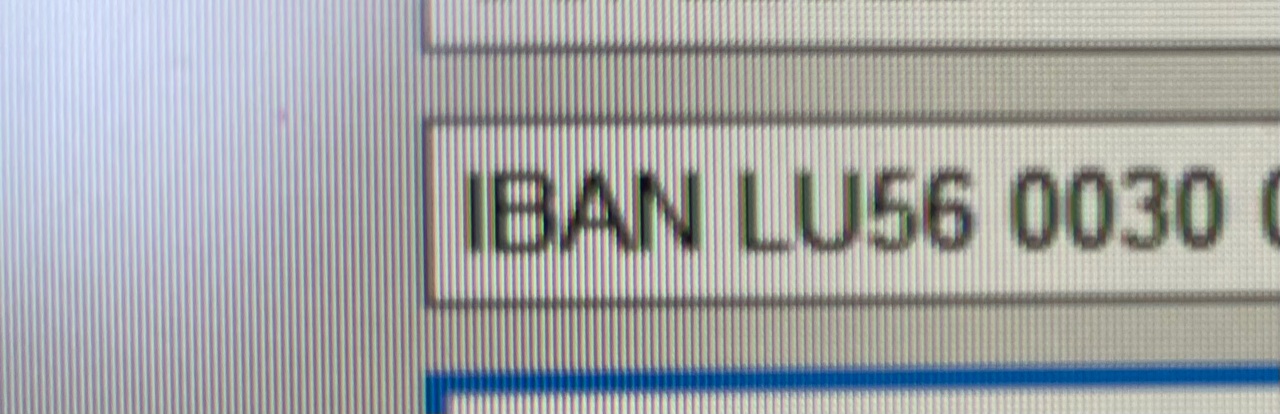
When I click right on the document extraction zone and hit "recognize", then the text extracted with the errors come back.
How is it possible that I have this behavior? Why don't I get directly the right text extracted without moving this extraction zone?
If someone could assist that would be extremely helpful!
Comments
3 comments
Technically when you load an image into FlexiCapture, it does a quick OCR of the whole page with the bare minimum setting. This is for FLS to run the logic. Like in FlexiLayout Studio, it does a precognition so you can build your search element logic. If you notice, the fonts setting don't match what you see in the DocDef. There is more recognition setting and option available in DocDef than FLS.
That being said, the 2 recognition results you are getting is when you lasso or click on the image is only using the bare OCR setting that is cached during the precognition. When you tell it to recognize, it will then use the setting in your DocDef field to help improve the recognition. i.e. If you know a field is only number, you can tell it that and it will sway the engine to only use number and shouldn't have a letter O vs a number Zero.
So to resolve your issue, play with the field Data type. You can specify an alphabet to help narrow down the recognition or even use a regular expression to say the beginning starts with a IBAN
Hello Scott,
Thanks for your answer! That makes sense.
Aaah so the bare OCR settings are better than the ones I've putted in the DocDef..! I've personalised the DataTypes and created a Regex. Maybe it's not that well made. It looks like this :
"IBAN"{0-1}"LU"[0-9]{18}
Does it look right to you?
Also it's strange that with the recognition, it has low confidence on the "3" but with the bare settings it is confident (the confidence level in the docDef is the default one at 60%)
It's out topic but still has to do with strange recognition behaviour. Do you have experience with fields that can be handprinted or typographic? I've selected in the field properties that it can be both, but sometimes it extract handprinted fields like it is typographic and the result is messed up. I was excepting Abbyy to make a clear distinction between the two.
I wouldn't say the bare OCR is the better one. In this case it is but with the full OCR setting you can get better OCR result by help narrowing it down. With the "bare" OCR what you get is what you get.
As for your regex I'm not sure how the pattern should be. Basically the way you have it set, you're saying that IBAN is optional and then you always have a LU and 18 digits. Is that what the field should be?
As for the low confidence level, keep in mind the "bare" OCR are using a different confidence level. I'm not sure what that is.
As for the mix field. Think of it this way. If you knw for sure that its hand print, tell the setting its hand print. Otherwise when you set it for both handprint and machine print, it has to run both recognition setting and decide based on quality. So if for some reason the engine feels the handprint setting has better results, then it chooses that option. It really dont if it handprint or machine unless you tell it. If you want it us possible to create the same region twice and set one for machine and another for handprint. Then you can decide which results you want.
Please sign in to leave a comment.