Using Abbyy finereader pdf 15 on some informal texts. Trying to batch convert hundreds of images into .txt files.
While the ORC accuracy is astounding, the results are all missing space between two sentences.
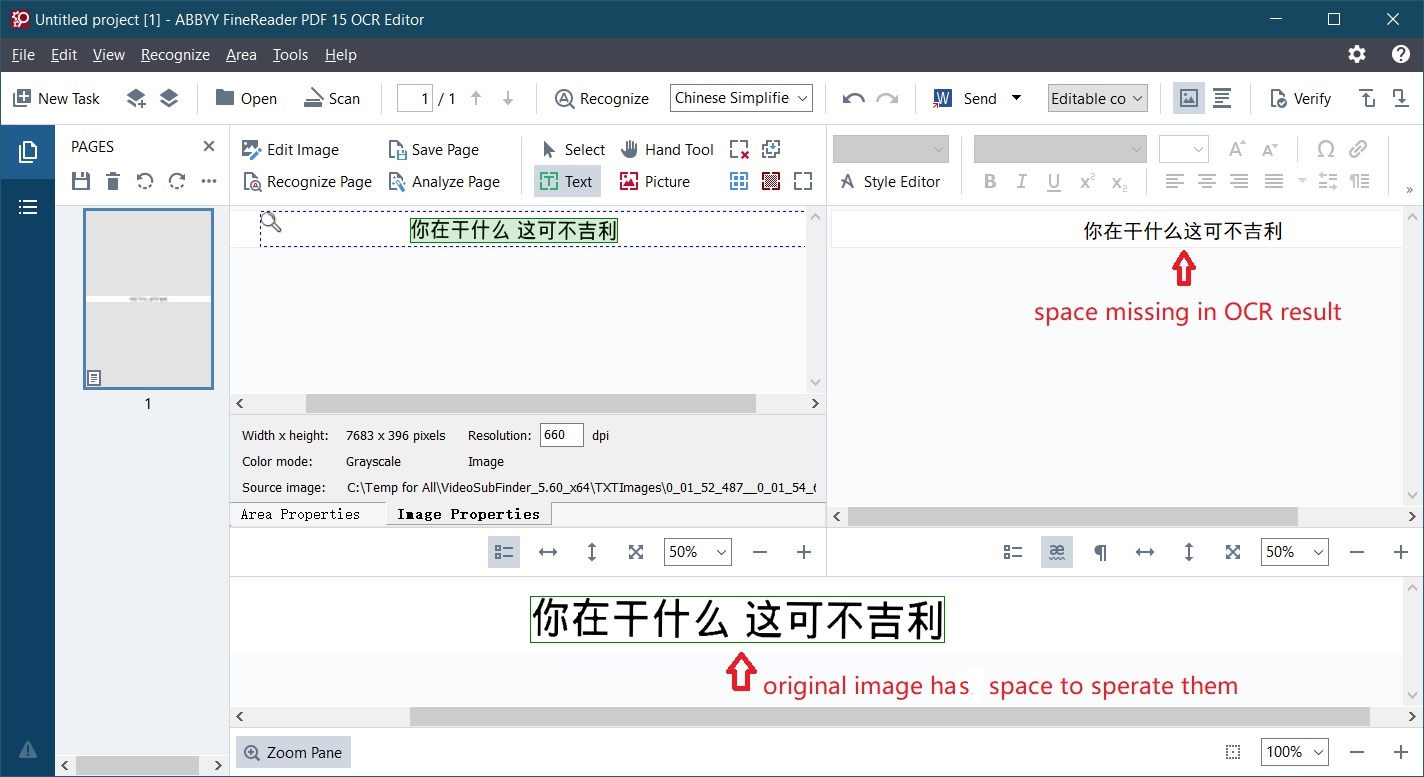
My guess would be the space is too minor that finereader ignored them during OCR. If I'm right, how can I twist the setting to adjust gap detection 🤔
Update:
After some more test, turns out if I crop the image to shrink it's width, finereader was able detect the space correctly.
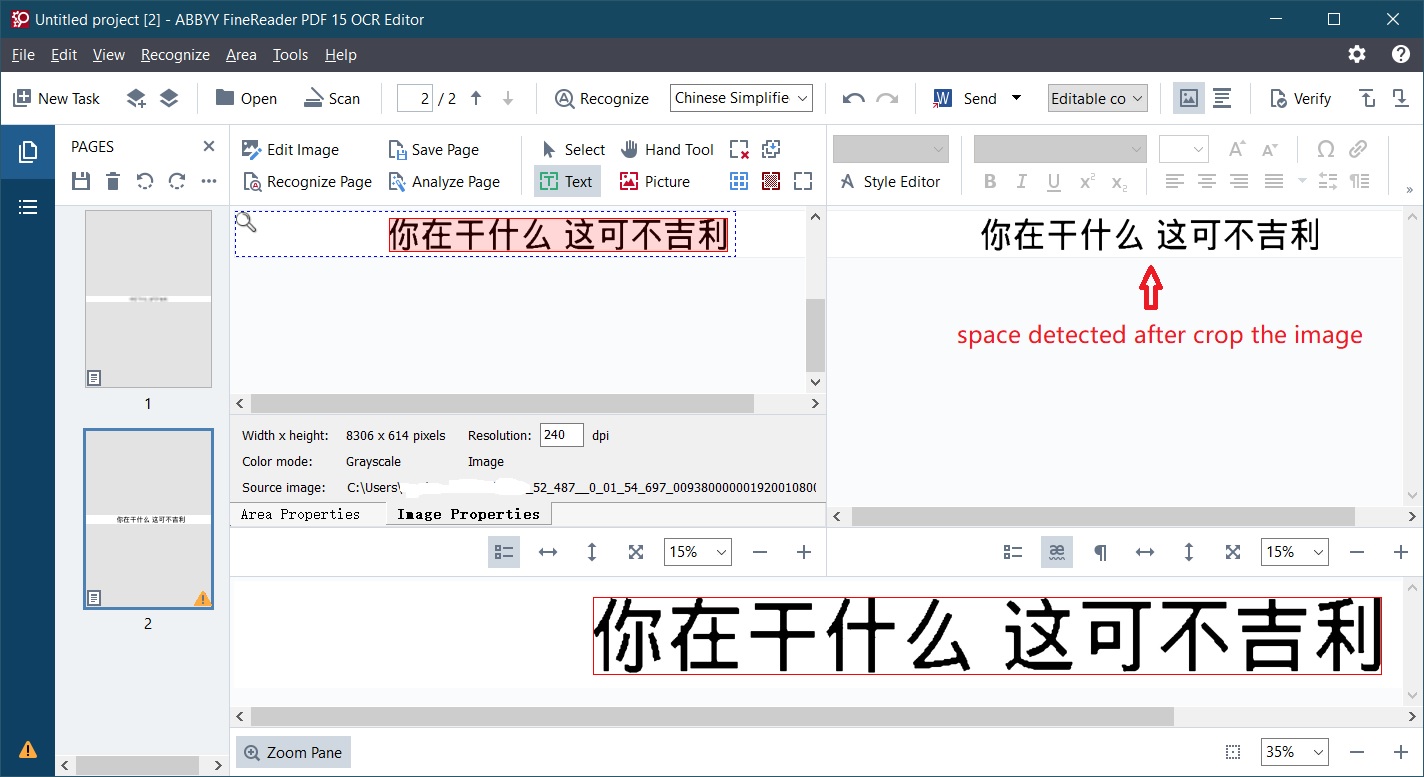
All I did is crop the image from the first demo (resolution: 7680*324) into 4153*307.
Can you provide some detail about how this works so that I can feed a better image for finereader to OCR.
Thanks in advance.
Update 2.0: upload image to Gdrive
https://drive.google.com/drive/folders/1qXcC8JY8ertTeKVyxz7bEIWtIqxAi9gj?usp=sharing
Comments
1 comment
Hello,
To analyze the issue we need a source file from you. I've created a support ticket for your question. Please await a reply from our Support Team.
Please sign in to leave a comment.