
文書にテキスト レイヤーのみを追加し、その画像の前処理を除外するには、以下の手順に沿ってください:
- FineReader PDF 15 (PDF エディター)でファイルを開きます。
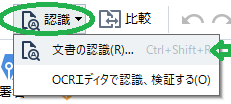
- 「認識」>「文書の認識」をクリックします。
- 適切なOCR言語を選択します。必要である場合には、「ページの向きを修正」と「画像の傾きと画像解像度の修正」の予備処理のオプションを有効にすることができます。
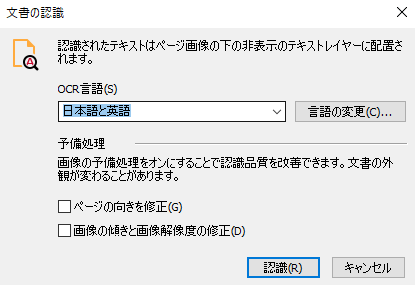
- 「認識」をクリックします。
- プログラムは文書にテキスト レイヤーを追加されました。ファイルを保存します。
保存する文書のファイル名には「_認識された」が付加されます。保存された検索可能なPDF文書のテキストを検索、選択、コピーできます。