I'm using processFields in Cloud OCR API to extract text from a PDF document.
Output XML contains extra spaces like this:
<value>MLTMRC5 7E2 9H2 6 4O</value>
while PDF text field is: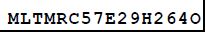
how can I prevent this?
I'm using processFields in Cloud OCR API to extract text from a PDF document.
Output XML contains extra spaces like this:
<value>MLTMRC5 7E2 9H2 6 4O</value>
while PDF text field is:
how can I prevent this?
0人中0人がこの記事が役に立ったと言っています
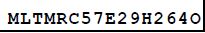{kind=link}
コメント
1件のコメント
Please try to use the following description for this text field in your XML file with recognition settings:
The oneTextLine element specifies whether the field contains only one text line. And the oneWordPerLine element specifies whether the field contains only one word in each text line.
Also in your case the letterSet and regExp elements of the text tag can be useful. Please see more details here.
Hope this will help!
サインインしてコメントを残してください。