
現象
Officeファイルをインポートすると、画像上テキストのない区域でテキストが認識されます。
例えば、FlexiLayout Studioでは、以下のように見えます:
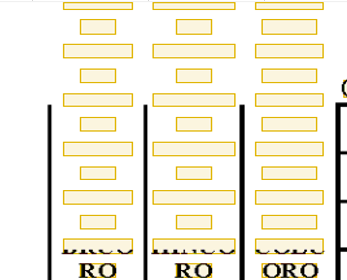
原因
FlexiCapture及びFlexiLayout Studioでは、Officeファイルをインポートする際、PDFに変換します。生成されるPDFはテキストレイヤ付きのPDFで、PDFファイルの処理設定(下図)に従って処理されます。ここで問題となるのが、生成されたPDFの画像上テキストの無い領域に(何らかの原因により)テキストレイヤが生成された場合で、本事象が発生する原因となります。
解決策
本事象が発生する事が事前に判明している場合、PDFファイルの処理設定を変更し、PDFファイルのテキストレイヤを使わず「OCRのみを使用」します。
FlexiLayout Studio の 設定:

FlexiCaptureのプロジェクトプロパティー:
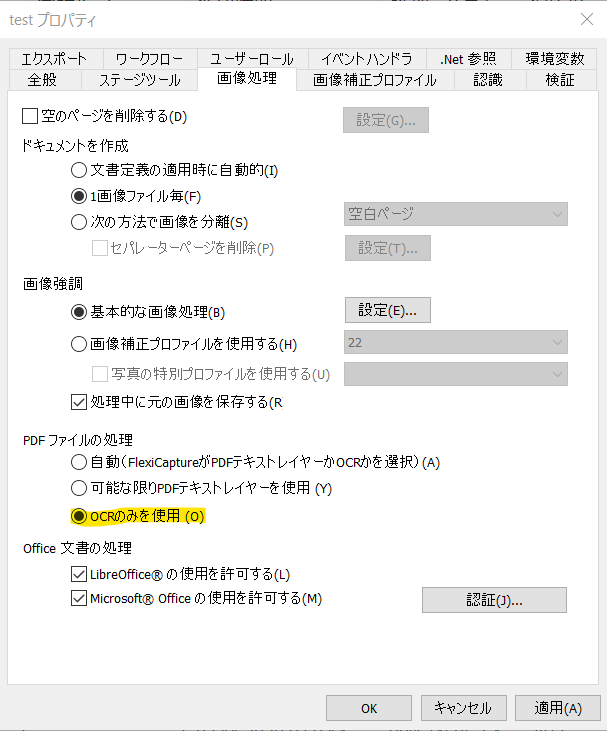
OCRのみを使用オプションをご選択ください。